
python开头的coding设置方法
缘起: [root@CentOS7 code] python multi_thread_mfw py File "multi_thread_mfw py", line 138SyntaxError: Non-ASCII character xe5 in file multi_thread_mfw py on line 138, but no encoding declared; see
缘起: [root@CentOS7 code] python multi_thread_mfw py File "multi_thread_mfw py", line 138SyntaxError: Non-ASCII character xe5 in file multi_thread_mfw py on line 138, but no encoding declared; see
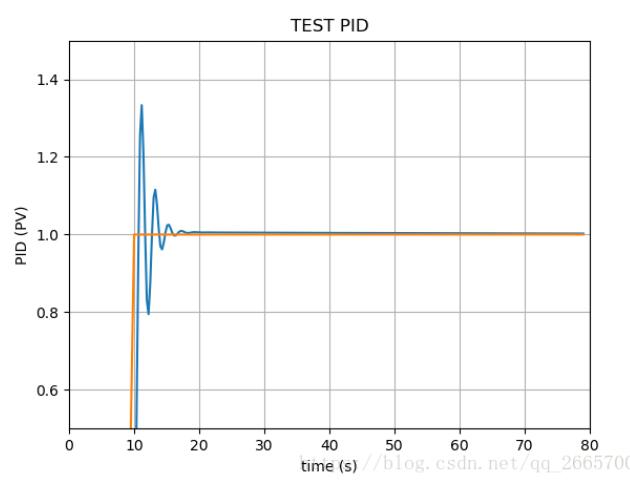
PID算法实现 import timeclass PID: def __init__(self, P=0 2, I=0 0, D=0 0): self Kp = P self Ki = I self Kd = D self sample_time = 0 00 self current_time = time time() self last_ti

python按行读取文件并找出其中指定字符串 coding=utf-8import os, time, sys, re reload(sys) sys setdefaultencoding("utf8") 不设置,否则编码方式不对应,无法找出字符串file = open(path)sum=0 for line in

本文实例讲述了Python使用百度翻译开发平台实现英文翻译为中文功能。分享给大家供大家参考,具体如下: coding=utf8import randomimport requestsimport hashlibappid = xxxxxxsecretKey = xxxxxdef get_md5(string):
我使用的python版本是3 5 2 今天想做个语音读取的小脚本,在网上查了一下发现python里有个pyttsx可以识别文字, 打算通过pip3 install pyttsx安装包,结果报错, 然后试了一下发现不行,去网上查了一下发现pyttsx3才行, pip3

由于工作需要本文主结合了excel表格,对表格中的ssh密码进行批量修改 以下是详细代码(python3): 遇到问题没人解答?小编创建了一个Python学习交流QQ群:857662006 寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习

简介: 本文介绍了图像检索的三种实现方式,均用python完成,其中前两种基于直方图比较,哈希法基于像素分布。 检索方式是:提前导入图片库作为检索范围,给出待检索的图片,将其与图片库中的图片进行比较,得出所有相似度后进行排
前言 由于今年暑假在学习一些自然语言处理的东西,发现网上对k-means的讲解不是很清楚,网上大多数代码只是将聚类结果以图片的形式呈现,而不是将聚类的结果表示出来,于是我将老师给的代码和网上的代码结合了一下,由于网上
例1 import osprint Process (%s) start %os getpid()pid = os fork()if pid==0: print I am child (%s) and my father is %s %(os getpid(),os getppid())else: print I (%s) just created a child process
如下所示: import osimport sysimport time processNmae = parent print "Program executing ntpid:%d,processNmae:%s"%(os gitpid(),processNmae) attempt to fork child processtry: forkPid = os fork()except