
pytorch numpy list类型之间的相互转换实例
如下所示: import torchfrom torch autograd import Variableimport numpy as nppytorch中Variable与torch Tensor类型的相互转换 1 torch Tensor转换成Variablea=torch randn((5,3))b=Variable(a)print(a,a type(
如下所示: import torchfrom torch autograd import Variableimport numpy as nppytorch中Variable与torch Tensor类型的相互转换 1 torch Tensor转换成Variablea=torch randn((5,3))b=Variable(a)print(a,a type(
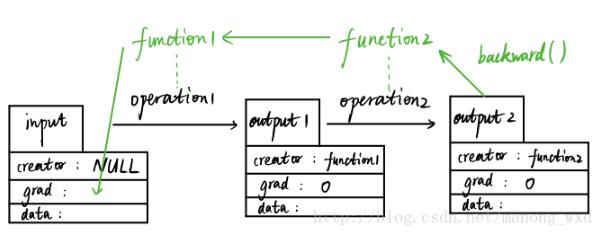
自动求导机制 从后向中排除子图 每个变量都有两个标志:requires_grad和volatile。它们都允许从梯度计算中精细地排除子图,并可以提高效率。 requires_grad 如果有一个单一的输入操作需要梯度,它的输出也需要梯度。相反,

torch nn Modules 相当于是对网络某种层的封装,包括网络结构以及网络参数和一些操作 torch nn Module 是所有神经网络单元的基类 查看源码 初始化部分: def __init__(self): self _backend = thnn_backend self _p

pytorch中我们有时候可能需要设定某些变量是参与训练的,这时候就需要查看哪些是可训练参数,以确定这些设置是成功的。 pytorch中model parameters()函数定义如下: def parameters(self): r"""Returns an iterator

前言 自从从深度学习框架caffe转到Pytorch之后,感觉Pytorch的优点妙不可言,各种设计简洁,方便研究网络结构修改,容易上手,比TensorFlow的臃肿好多了。对于深度学习的初学者,Pytorch值得推荐。今天主要主要谈谈Pytorch是如
Embedding 词嵌入在 pytorch 中非常简单,只需要调用 torch nn Embedding(m, n) 就可以了,m 表示单词的总数目,n 表示词嵌入的维度,其实词嵌入就相当于是一个大矩阵,矩阵的每一行表示一个单词。 emdedding初始化 默认是随
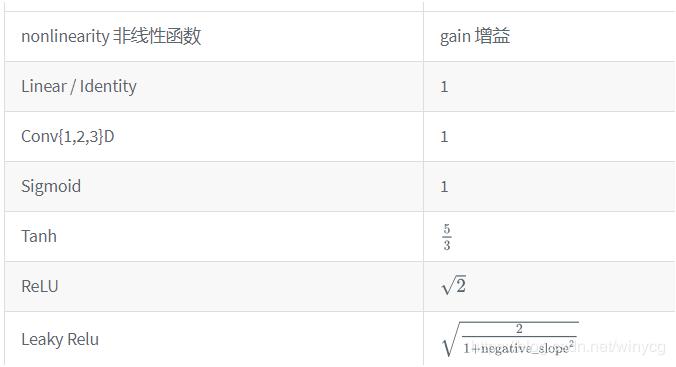
º¯ÊýµÄÔöÒæÖµ torch nn init calculate_gain(nonlinearity, param=None) ÌṩÁ˶ԷÇÏßÐÔº¯ÊýÔöÒæÖµµÄ¼ÆËã¡£ ÔöÒæÖµgainÊÇÒ»¸ö±ÈÀýÖµ£¬À´µ
本文源码基于版本1 0,交互界面基于0 4 1 import torch 按照指定轴上的坐标进行过滤 index_select() 沿着某tensor的一个轴dim筛选若干个坐标 >>> x = torch randn(3, 4) 目标矩阵>>> xtensor([[ 0 1427, 0 0231, -
1 Pytorch风格的索引 根据Tensor的shape,从前往后索引,依次在每个维度上做索引。 示例代码: import torch a = torch rand(4, 3, 28, 28)print(a[0] shape) 取到第一个维度print(a[0, 0] shape) 取到二个维度print

在PyTorch中可以对图像和Tensor进行填充,如常量值填充,镜像填充和复制填充等。在图像预处理阶段设置图像边界填充的方式如下: import vision torchvision transforms as transforms img_to_pad = transforms Compose([