
python爬虫 基于requests模块的get请求实现详解
需求:爬取搜狗首页的页面数据 import requests 1 指定urlurl = https: www sogou com 2 发起get请求:get方法会返回请求成功的响应对象response = requests get(url=url) 3 获取响应中的数据:text属性作用是可以
需求:爬取搜狗首页的页面数据 import requests 1 指定urlurl = https: www sogou com 2 发起get请求:get方法会返回请求成功的响应对象response = requests get(url=url) 3 获取响应中的数据:text属性作用是可以

函数的作用域 python中的作用域分4种情况: L:local,局部作用域,即函数中定义的变量; E:enclosing,嵌套的父级函数的局部作用域,即包含此函数的上级函数的局部作用域,但不是全局的; G:globa,全局变量,就是模块级别定义的变量; B:bu
1 [文件] DakeleSign py ~ 4KB ! usr bin env python -*- coding: utf-8 -*-__author__ = poppydakele bbs siginimport sysimport urllib2import urllibimport requestsimport cookielibimport jsonfrom pyquery

非阻塞IO(non-blocking IO) Linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子: 从图中可以看出,当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么
实际应用时可能比较想获取VGG中间层的输出, 那么就可以如下操作: import numpy as npimport torchfrom torchvision import modelsfrom torch autograd import Variableimport torchvision transforms as transforms
这是一个用python写解压大量zip脚本的说明,本人新手一个,希望能对各位有所启发。 首先要注意的,在运行自己的脚本之前一定先备份或者复制出一些样本进行测试,不然出错会很麻烦; 之后我用到的是解压zip文件的扩展包zipfile

这边我是需要得到图片在Vgg的5个block里relu后的Feature Map (其余网络只需要替换就可以了) 索引可以这样获得 vgg = models vgg19(pretrained=True) features eval()print (vgg) Feature Map可利用下面的class cla
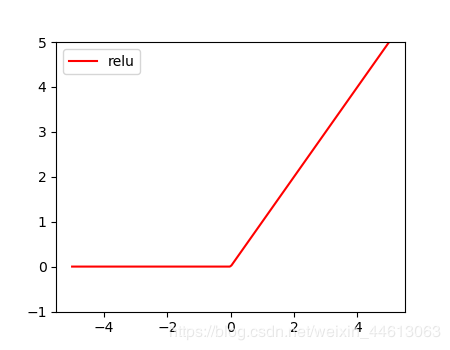
神经网络只是由两个或多个线性网络层叠加,并不能学到新的东西,简单地堆叠网络层,不经过非线性激活函数激活,学到的仍然是线性关系。 但是加入激活函数可以学到非线性的关系,就具有更强的能力去进行特征提取。 构造数据 i
阻塞IO(blocking IO) 在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样: 当用户进程调用了recvfrom这个系统调用,kernel内核就开始了IO的第一个阶段:准备数据。对于network io( 网络io )来说

一 multiprocessing模块介绍 python中的多线程无法利用多核优势,如果想要充分地使用多核CPU的资源(os cpu _count ( )查看),在python中大部分情况需要使用多进程。 Python提供了multiprocessing。 multiprocessing模块