
python3.7+scrapy1.5+docker Toolbox+Splash v3.2+scrapy-spl抓取js 动态网页简单实例
win7+ python3.7 + scrapy1.5 + docker Toolbox + Splash v3.2 + scrapy-splash说明:Splash v3.2安装在docker Toolbox虚拟容器中,其他直接安装在win7系统
win7+ python3.7 + scrapy1.5 + docker Toolbox + Splash v3.2 + scrapy-splash说明:Splash v3.2安装在docker Toolbox虚拟容器中,其他直接安装在win7系统
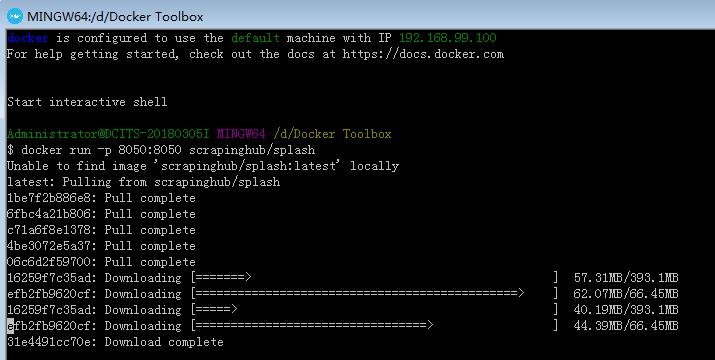
windows7 + Docker ToolBox + Scrapy Splash windows10 + 原生的Docker + Scrapy Splash 原生的Docker :系统要求,Windows10x64位,支持Hyper-V
time.time()返回的是浮点数,单位秒。但是strftime处理的类型是time.struct_time,实际上是一个tuple元组,strptime和localtime都会返回此元组类型
一个scarpy简易的spider爬虫蜘蛛

执行scarpy爬虫蜘蛛提示import win32api ModuleNotFoundError No module named 'win32api'
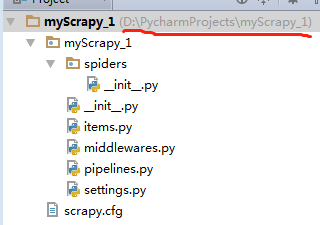
执行类似scrapy startproject myScrapy_1命令,myScrapy_1为项目名称
提示错误:error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools
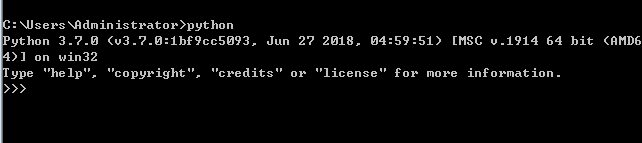
官方地址下载https://www.python.org/downloads/release/python-370/下载之后为exe格式文件,双击按照步骤安装安装成功cmd输入python

windows 7 系统下爬虫抓取提示如下错误& 39;gbk& 39; codec can& 39;t encode character & 39; xa0& 39; 对于此Unicode字符(myUnWebItems),需要print出来的话,由于本地系统是Windows中的cmd,默认codepage是CP936,即GBK的编
Python3 爬虫 BeautifulSoup模块(4): bs4 Tag类型转换为字符串 insert插入数据错误 cur execute( "insert into p_links(title,href,content) values ( %s , %s , %s ) " % (titleContents,full_url,cont_p))