
深入浅出 Python 中文版.pdf电子书下载
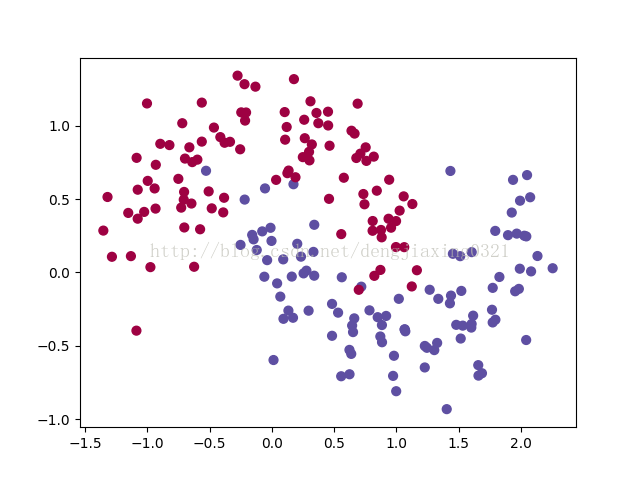
获取数据集,并画图代码如下:
import numpy as np from sklearn.datasets import make_moons import matplotlib.pyplot as plt # 手动生成一个随机的平面点分布,并画出来 np.random.seed(0) X, y = make_moons(200, noise=0.20) plt.scatter(X[:,0], X[:,1], s=40, c=y, cmap=plt.cm.Spectral) plt.show()
得到图如下:
定义决策边界函数:
# 咱们先顶一个一个函数来画决策边界 def plot_decision_boundary(pred_func): # 设定最大最小值,附加一点点边缘填充 x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5 y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5 h = 0.01 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) # 用预测函数预测一下 Z = pred_func(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) # 然后画出图 plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral) plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Spectral)
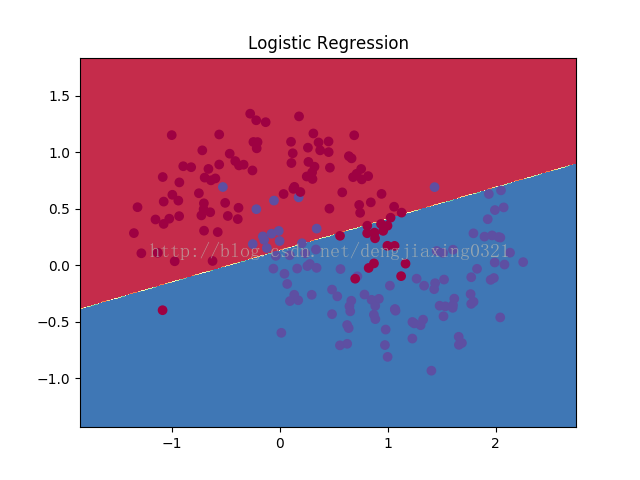
定义分类函数,并画出决策边界图代码如下:
from sklearn.linear_model import LogisticRegressionCV
#咱们先来瞄一眼逻辑斯特回归对于它的分类效果
clf = LogisticRegressionCV()
clf.fit(X, y)
# 画一下决策边界
plot_decision_boundary(lambda x: clf.predict(x))
plt.title("Logistic Regression")
plt.show()
画图如下:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持谷谷点程序。
转载请注明:谷谷点程序 » python 画出使用分类器得到的决策边界