
python进阶pdf电子书下载
ÒÔÏÂʵÑéÊÇÎÒÔڰٶȹ«Ë¾ÊµÏ°µÄʱºò×öµÄ£¬¼Ç¼ÏÂÀ´Áô¸öС¾Ñé¡£
¶àGPUѵÁ·
cifar10_97.23 ʹÓà run.sh Îļþ¿ªÊ¼ÑµÁ·
cifar10_97.50 ʹÓà run.4GPU.sh ¿ªÊ¼ÑµÁ·
ÔÚ¼¯ÈºÖиıäGPUµ÷ÓøöÊýÐÞ¸Ä run.sh Îļþ
nohup srun --job-name=cf23 $pt --gres=gpu:2 -n1 bash cluster_run.sh $cmd 2>&1 1>>log.cf50_2GPU &
ÐÞ¸Ä ¨Cgres=gpu:2 ¼´¿É
Python Îļþ´úÂëÐÞ¸Ä
parser.add_argument('--batch_size', type=int, default=96*2, help='batch size')
Ð޸ĶÔÓ¦ batch size ´óС£¬±£Ö¤Ã¿¿éGPU»ñµÃµÈÁ¿µÄѵÁ·Êý¾Ý£¬ÒòΪbatch_sizeµÄ¸Ä±ä»áÓ°ÏìѵÁ·¾«¶È
×îÈÝÒ×ʵÏֵĵ¥GPUѵÁ·¸ÄΪ¶àGPUѵÁ·´úÂë
µ¥GPU£ºlogits, logits_aux = model(input)
¶àGPU£º
if torch.cuda.device_count()>1:#ÅжÏÊÇ·ñÄܹ»ÓдóÓÚÒ»µÄGPU×ÊÔ´¿ÉÒÔµ÷Óà logits, logits_aux =nn.parallel.data_parallel(model,input) else: logits, logits_aux = model(input)
ȱµã£º²»ÊÇÐÔÄÜ×îºÃµÄʵÏÖ·½Ê½
Óŵ㣺´úÂëǶÈëÊÊÓ¦ÐÔÇ¿£¬²»ÈÝÒ×±¨´í
ÐÔÄÜ·ÖÎö
¸ÃͼΪ1µ½8GPUѵÁ·cifar10¡ª¡ª97.23ÍøÂçµÄʵÑé¶Ô±È
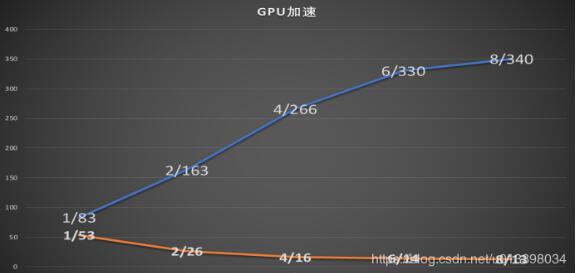
¿ÉÒÔ¿´µ½µ¥ºËѵÁ·600ÂÖÐèÒª53Сʱ¡¢Ë«ºËѵÁ·600ÂÖÐèÒª26Сʱ¡¢ËĺË16¡¢ÁùºË14¡¢°ËºË13¡£
ÔÚ¿ÉÔËÐÐ7СʱµÄGPUÉϵĶԱÈʵÑ飺µ¥ºËÅÜÍê83ÂÖ¡¢Ë«ºËÅÜÍê163ÂÖ¡¢ËĺËÅÜÍê266ÂÖ
½áÂÛ£ºÐԼ۱ȽϸߵÄÊÇʹÓÃ4¡«6ºËGPU½øÐÐѵÁ·£¬µ«ÊǶàGPUѵÁ·¶ÔÓÚµ¥GPUѵÁ·ÓÐËù²îÒ죬ѵÁ·µÄ׼ȷÂÊÌáÉý»áÓÐËù²¨¶¯£¬Ä¿Ç°·¢ÏÖµÄÊǸºÃæµÄÓ°Ïì¡£
ÒÔÉÏÕâƪ¹ØÓÚpytorch¶àGPUѵÁ·ÊµÀýÓëÐÔÄܶԱȷÖÎö¾ÍÊÇС±à·ÖÏí¸ø´ó¼ÒµÄÈ«²¿ÄÚÈÝÁË£¬Ï£ÍûÄܸø´ó¼ÒÒ»¸ö²Î¿¼£¬Ò²Ï£Íû´ó¼Ò¶à¶àÖ§³Ö½Å±¾Ö®¼Ò¡£
转载请注明:谷谷点程序 » 关于pytorch多GPU训练实例与性能对比分析