
Python Cookbook中文版电子书下载
º¯ÊýµÄÔöÒæÖµ
torch.nn.init.calculate_gain(nonlinearity, param=None)
ÌṩÁ˶ԷÇÏßÐÔº¯ÊýÔöÒæÖµµÄ¼ÆËã¡£
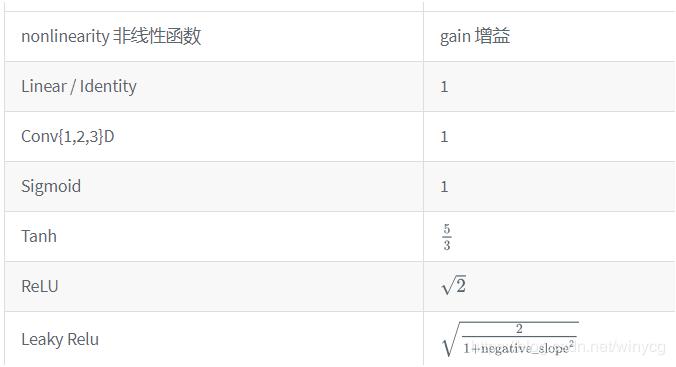
ÔöÒæÖµgainÊÇÒ»¸ö±ÈÀýÖµ£¬À´µ÷¿ØÊäÈëÊýÁ¿¼¶ºÍÊä³öÊýÁ¿¼¶Ö®¼äµÄ¹Øϵ¡£
fan_inºÍfan_out
pytorch¼ÆËãfan_inºÍfan_outµÄÔ´Âë
def _calculate_fan_in_and_fan_out(tensor):
dimensions = tensor.ndimension()
if dimensions < 2:
raise ValueError("Fan in and fan out can not be computed
for tensor with fewer than 2 dimensions")
if dimensions == 2: # Linear
fan_in = tensor.size(1)
fan_out = tensor.size(0)
else:
num_input_fmaps = tensor.size(1)
num_output_fmaps = tensor.size(0)
receptive_field_size = 1
if tensor.dim() > 2:
receptive_field_size = tensor[0][0].numel()
fan_in = num_input_fmaps * receptive_field_size
fan_out = num_output_fmaps * receptive_field_size
return fan_in, fan_out

xavier·Ö²¼
xavier·Ö²¼½âÎö£ºhttps://prateekvjoshi.com/2016/03/29/understanding-xavier-initialization-in-deep-neural-networks/
¼ÙÉèʹÓõÄÊÇsigmoidº¯Êý¡£µ±È¨ÖØÖµ(ÖµÖ¸µÄÊǾø¶ÔÖµ)¹ýС£¬ÊäÈëֵÿ¾¹ýÍøÂç²ã£¬·½²î¶¼»á¼õÉÙ£¬Ã¿Ò»²ãµÄ¼ÓȨºÍºÜС£¬ÔÚsigmoidº¯Êý0¸½¼þµÄÇøÓòÏ൱ÓÚÏßÐÔº¯Êý£¬Ê§È¥ÁËDNNµÄ·ÇÏßÐÔÐÔ¡£
µ±È¨ÖصÄÖµ¹ý´ó£¬ÊäÈëÖµ¾¹ýÿһ²ãºó·½²î»áѸËÙÉÏÉý£¬Ã¿²ãµÄÊä³öÖµ½«»áºÜ´ó£¬´Ëʱÿ²ãµÄÌݶȽ«»áÇ÷½üÓÚ0.
xavier³õʼ»¯¿ÉÒÔʹµÃÊäÈëÖµx x x<math><semantics><mrow><mi>x</mi></mrow><annotation encoding="application/x-tex">x</annotation></semantics></math>x·½²î¾¹ýÍøÂç²ãºóµÄÊä³öÖµy y y<math><semantics><mrow><mi>y</mi></mrow><annotation encoding="application/x-tex">y</annotation></semantics></math>y·½²î²»±ä¡£
£¨1£©xavierµÄ¾ùÔÈ·Ö²¼
torch.nn.init.xavier_uniform_(tensor, gain=1)
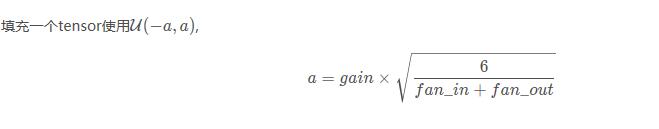
Ò²³ÆΪGlorot initialization¡£
>>> w = torch.empty(3, 5)
>>> nn.init.xavier_uniform_(w, gain=nn.init.calculate_gain('relu'))
(2) xavierÕý̬·Ö²¼
torch.nn.init.xavier_normal_(tensor, gain=1)
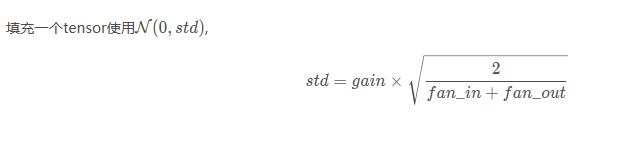
Ò²³ÆΪGlorot initialization¡£
kaiming·Ö²¼
XavierÔÚtanhÖбíÏֵĺܺ㬵«ÔÚRelu¼¤»îº¯ÊýÖбíÏֵĺܲËùºÎ¿Ã÷Ìá³öÁËÕë¶ÔÓÚreluµÄ³õʼ»¯·½·¨¡£pytorchĬÈÏʹÓÃkaimingÕý̬·Ö²¼³õʼ»¯¾í»ý²ã²ÎÊý¡£
(1) kaiming¾ùÔÈ·Ö²¼
torch.nn.init.kaiming_uniform_ (tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')

Ò²±»³ÆΪ He initialization¡£
a ¨C the negative slope of the rectifier used after this layer (0 for ReLU by default).¼¤»îº¯ÊýµÄ¸ºÐ±ÂÊ£¬
mode ¨C either ¡®fan_in' (default) or ¡®fan_out'. Choosing fan_in preserves the magnitude of the variance of the weights in the forward pass. Choosing fan_out preserves the magnitudes in the backwards
pass.ĬÈÏΪfan_inģʽ£¬fan_in¿ÉÒÔ±£³ÖÇ°Ïò´«²¥µÄȨÖØ·½²îµÄÊýÁ¿¼¶£¬fan_out¿ÉÒÔ±£³Ö·´Ïò´«²¥µÄȨÖØ·½²îµÄÊýÁ¿¼¶¡£
>>> w = torch.empty(3, 5) >>> nn.init.kaiming_uniform_(w, mode='fan_in', nonlinearity='relu')
(2) kaimingÕý̬·Ö²¼
torch.nn.init.kaiming_normal_ (tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')
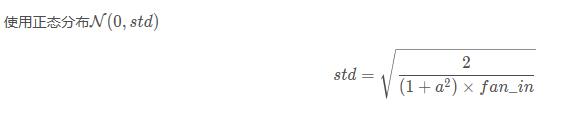
Ò²±»³ÆΪ He initialization¡£
>>> w = torch.empty(3, 5) >>> nn.init.kaiming_normal_(w, mode='fan_out', nonlinearity='relu')
ÒÔÉÏÕâƪ¶ÔPytorchÉñ¾ÍøÂç³õʼ»¯kaiming·Ö²¼Ïê½â¾ÍÊÇС±à·ÖÏí¸ø´ó¼ÒµÄÈ«²¿ÄÚÈÝÁË£¬Ï£ÍûÄܸø´ó¼ÒÒ»¸ö²Î¿¼£¬Ò²Ï£Íû´ó¼Ò¶à¶àÖ§³Ö½Å±¾Ö®¼Ò¡£
转载请注明:谷谷点程序 » 对Pytorch神经网络初始化kaiming分布详解