
python基于pdfminer库提取pdf文字代码实例
安装pdfminer 库 windows 下安装pdfminer3k pip install pdfminer3k Liunx 下安装pdfminer pip install pdfminer 代码 from pdfminer pdfparser import PDFParser, PDFDocumentfrom pdfminer converter impo
安装pdfminer 库 windows 下安装pdfminer3k pip install pdfminer3k Liunx 下安装pdfminer pip install pdfminer 代码 from pdfminer pdfparser import PDFParser, PDFDocumentfrom pdfminer converter impo
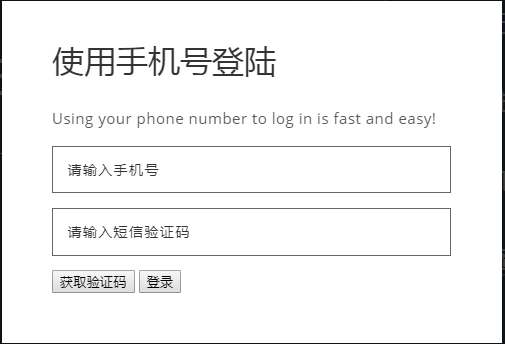
本文使用聚合数据的短信接口,需要先获取到申请接口的appkey和模板id 项目目录下创建ubtils文件夹,定义返回随机验证码和调取短信接口的函数 function py文件 import randomimport re 随机数def range_num(num):

1、合并列表(extend) 跟元组一样,用加号(+)将两个列表加起来即可实现合并: In [1]: x=list(range(1, 13, 2))In [2]: x + [b, a]Out[2]: [1, 3, 5, 7, 9, 11, b, a] 对于已定义的列表,可以用extend方法一次性添加多个元素
centos7之Python3 74安装 安装版本:Python3 74 系统版本:centos7 系统默认安装Python2 7,保留。 安装 usr bin Python3 安装需要root权限。 安装Python3的准备工作: 1、安装编译python3所用到的相关依赖包: yum install

当我们的资产放在交易所的时候,可以通过链接交易所的API使用Python来监控余额。 那资产放在钱包的时候,如何来监控余额呢? 任何数字资产都可以使用区块浏览器来查询余额,那我们只要从此着手,用Python调取区块浏览器,来查询

Manager支持的类型有 list,dict,Namespace,Lock,RLock,Semaphore,BoundedSemaphore,Condition,Event,Queue,Value和Array。 但当使用Manager处理list、dict等可变数据类型时,需要注意一个陷阱,即Manager对象无法监测到

问题 https: docs python org 3 tutorial errors html handling-exceptions https: docs python org 3 library exceptions html ValueError try: int("x")except Exception as e: 异常的父类,可以捕获所有的异

昨日内容: ORM高级查询 -filterid=3id__gt=3id__lt=3id__lte=3id__gte=3-in not in filter(id__in=[]) in exclude(id__in=[]) not in-between and filter(id__range=[])-like filter(name__startswith=XX) li
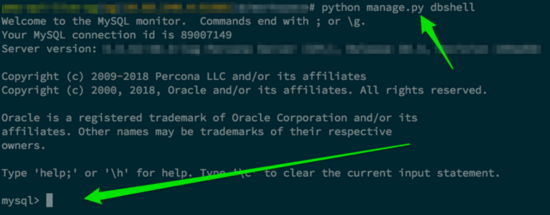
实际工作经历中,免不了有时候需要连接数据库进行问题排查分析的场景,之前一直习惯通过 mysql -uxxx -hxxxx -P1234 这样的方式来启动命令行形式的 MySQL 数据库客户端程序,只是用起来比较麻烦,每次都要拷贝各个配置
原理 使用python win32 库 调用word底层vba,将word转成pdf 安装pywin32 pip install pywin32 python代码 from win32com client import gencachefrom win32com client import constants, gencachedef createPd