
基于pytorch的保存和加载模型参数的方法
当我们花费大量的精力训练完网络,下次预测数据时不想再(有时也不必再)训练一次时,这时候torch save(),torch load()就要登场了。 保存和加载模型参数有两种方式: 方式一: torch save(net state_dict(),path): 功能:保存训练
当我们花费大量的精力训练完网络,下次预测数据时不想再(有时也不必再)训练一次时,这时候torch save(),torch load()就要登场了。 保存和加载模型参数有两种方式: 方式一: torch save(net state_dict(),path): 功能:保存训练

pytorch 输出中间层特征: tensorflow输出中间特征,2种方式: 1 保存全部模型(包括结构)时,需要之前先add_to_collection 或者 用slim模块下的end_points 2 只保存模型参数时,可以读取网络结构,然后按照对应的中间层输出即

如下所示: 一 visualize py from graphviz import Digraphimport torchfrom torch autograd import Variable def make_dot(var, params=None): """ Produces Graphviz representation of PyTorch autograd graph

方法一:手动计算变量的梯度,然后更新梯度 import torchfrom torch autograd import Variable 定义参数w1 = Variable(torch FloatTensor([1,2,3]),requires_grad = True) 定义输出d = torch mean(w1) 反向求导d ba
torch optim 是一个实现了各种优化算法的库。大部分常用的方法得到支持,并且接口具备足够的通用性,使得未来能够集成更加复杂的方法。 使用 torch optim,必须构造一个 optimizer 对象。这个对象能保存当前的参数状态并
简而言之就是,nn Sequential类似于Keras中的贯序模型,它是Module的子类,在构建数个网络层之后会自动调用forward()方法,从而有网络模型生成。而nn ModuleList仅仅类似于pytho中的list类型,只是将一系列层装入列表,并没有实
如下所示: import torchfrom torch autograd import Variableimport numpy as nppytorch中Variable与torch Tensor类型的相互转换 1 torch Tensor转换成Variablea=torch randn((5,3))b=Variable(a)print(a,a type(
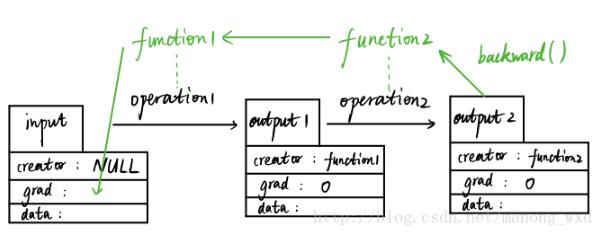
自动求导机制 从后向中排除子图 每个变量都有两个标志:requires_grad和volatile。它们都允许从梯度计算中精细地排除子图,并可以提高效率。 requires_grad 如果有一个单一的输入操作需要梯度,它的输出也需要梯度。相反,

torch nn Modules 相当于是对网络某种层的封装,包括网络结构以及网络参数和一些操作 torch nn Module 是所有神经网络单元的基类 查看源码 初始化部分: def __init__(self): self _backend = thnn_backend self _p

pytorch中我们有时候可能需要设定某些变量是参与训练的,这时候就需要查看哪些是可训练参数,以确定这些设置是成功的。 pytorch中model parameters()函数定义如下: def parameters(self): r"""Returns an iterator