
PyTorch中Tensor的维度变换实现
对于 PyTorch 的基本数据对象 Tensor (张量),在处理问题时,需要经常改变数据的维度,以便于后期的计算和进一步处理,本文旨在列举一些维度变换的方法并举例,方便大家查看。 维度查看:torch Tensor size() 查看当前 tensor
对于 PyTorch 的基本数据对象 Tensor (张量),在处理问题时,需要经常改变数据的维度,以便于后期的计算和进一步处理,本文旨在列举一些维度变换的方法并举例,方便大家查看。 维度查看:torch Tensor size() 查看当前 tensor

pytorchÖеÄgatherº¯Êý pytorch±Ètensorflow¸ü¼Ó±à³ÌÓѺã¬ËùÒÔ×¼±¸ÓÃpytorchÊÔ×Å×ö×î½üÒª×öµÄһЩʵÑé¡£ Á¢¸öflag¿ªÊ¼Ñ§Ï°pytorch£¬

index_select anchor_w = self FloatTensor(self scaled_anchors) index_select(1, self LongTensor([0])) 参数说明:index_select(x, 1, indices) 1代表维度1,即列,indices是筛选的索引序号。 例子: import torch x =
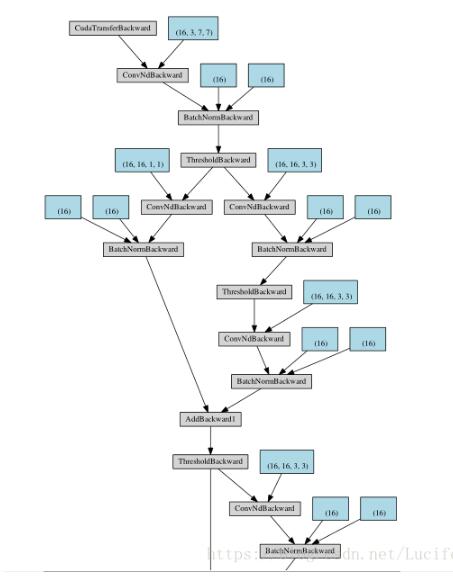
最简单的方法当然可以直接print(net),但是这样网络比较复杂的时候效果不太好,看着比较乱;以前使用caffe的时候有一个网站可以在线生成网络框图,tensorflow可以用tensor board,keras中可以用model summary()、或者plot_model

一个继承nn module的model它包含一个叫做children()的函数,这个函数可以用来提取出model每一层的网络结构,在此基础上进行修改即可,修改方法如下(去除后两层): resnet_layer = nn Sequential(*list(model children())[:
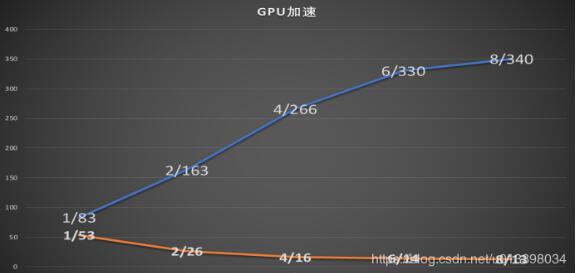
ÒÔÏÂʵÑéÊÇÎÒÔڰٶȹ«Ë¾ÊµÏ°µÄʱºò×öµÄ£¬¼Ç¼ÏÂÀ´Áô¸öС¾Ñé¡£ ¶àGPUѵÁ· cifar10_97 23 ʹÓà run sh Îļþ¿ªÊ¼ÑµÁ· cifar10_97
本文适合多GPU的机器,并且每个用户需要单独使用GPU训练。 虽然pytorch提供了指定gpu的几种方式,但是使用不当的话会遇到out of memory的问题,主要是因为pytorch会在第0块gpu上初始化,并且会占用一定空间的显存。这种情况

pytorch指定GPU 在用pytorch写CNN的时候,发现一运行程序就卡住,然后cpu占用率100%,nvidia-smi 查看显卡发现并没有使用GPU。所以考虑将模型和输入数据及标签指定到gpu上。 pytorch中的Tensor和Module可以指定gpu运行,并
如下所示: device = torch device("cuda:0" if torch cuda is_available() else "cpu") 第一行代码model to(device) 第二行代码 首先是上面两行代码放在读取数据之前。 mytensor = my_tensor to(device) 第三行代
最近将Pytorch程序迁移到GPU上去的一些工作和思考 环境:Ubuntu 16 04 3 Python版本:3 5 2 Pytorch版本:0 4 0 0 序言 大家知道,在深度学习中使用GPU来对模型进行训练是可以通过并行化其计算来提高运行效率,这里就不多谈