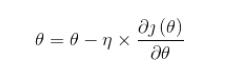
关于pytorch中网络loss传播和参数更新的理解
相比于2018年,在ICLR2019提交论文中,提及不同框架的论文数量发生了极大变化,网友发现,提及tensorflow的论文数量从2018年的228篇略微提升到了266篇,keras从42提升到56,但是pytorch的数量从87篇提升到了252篇。 TensorFlow:
相比于2018年,在ICLR2019提交论文中,提及不同框架的论文数量发生了极大变化,网友发现,提及tensorflow的论文数量从2018年的228篇略微提升到了266篇,keras从42提升到56,但是pytorch的数量从87篇提升到了252篇。 TensorFlow:

多路复用IO(IO multiplexing) 这种IO方式为事件驱动IO(event driven IO)。 我们都知道,select epoll的好处就在于单个进程process就可以同时处理多个网络连接的IO。它的基本原理就是select epoll这个function会不断
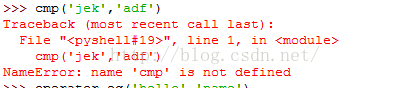
python 3 4 3 的版本中已经没有cmp函数,被operator模块代替,在交互模式下使用时,需要导入模块。 在没有导入模块情况下,会出现 提示找不到cmp函数了,那么在python3中该如何使用这个函数呢?所以要导入模块 看下面给的
logging库提供了两个可以用于日志滚动的class(可以参考https: docs python org 2 library logging handlers html),一个是RotatingFileHandler,它主要是根据日志文件的大小进行滚动,另一个是TimeRotatingFileHandler,它主

Pytorch 训练时有时候会因为加载的东西过多而爆显存,有些时候这种情况还可以使用cuda的清理技术进行修整,当然如果模型实在太大,那也没办法。 使用torch cuda empty_cache()删除一些不需要的变量代码示例如下: try: ou

前提:我训练的是二分类网络,使用语言为pytorch Varibale包含三个属性: data:存储了Tensor,是本体的数据 grad:保存了data的梯度,本事是个Variable而非Tensor,与data形状一致 grad_fn:指向Function对象,用于反向传播的梯度计算

一 Process对象的join方法 在主进程运行过程中如果想并发地执行其他的任务,我们可以开启子进程,此时主进程的任务与子进程的任务分两种情况 情况一: 在主进程的任务与子进程的任务彼此独立的情况下,主进程的任务先执行
摘要 global 标志实际上是为了提示 python 解释器,表明被其修饰的变量是全局变量。这样解释器就可以从当前空间 (current scope) 中读写相应变量了。 Python 的全局变量是模块 (module) 级别的 每个 python 函数拥
Python的数据结构有列表、元组、集合、字典等,可以吧列表当成一个清单,是有序的,我们可以通过索引访问到列表中的元素,列表还可以进行修改、新增和删除的操作。列表中的数据类型是不限制的,可以是字符串、数值等,不要求必

本文实例为大家分享了python+tkinter实现学生管理系统的具体代码,供大家参考,具体内容如下 from tkinter import *from tkinter messagebox import *import sqlite3from tkinter import ttk dbstr = "H: mydb db"