
python递归下载文件夹下所有文件
最近想备份网站,但是php下载文件的大小是有大小限制的,而我也懒得装ftp再下载了,就想着暂时弄个二级域名站,然后用python(python3)的requests库直接下载网站根目录下的所有文件以及文件夹。(0-0就是这么任性) 1 安装reques
最近想备份网站,但是php下载文件的大小是有大小限制的,而我也懒得装ftp再下载了,就想着暂时弄个二级域名站,然后用python(python3)的requests库直接下载网站根目录下的所有文件以及文件夹。(0-0就是这么任性) 1 安装reques

最近写了一个网络验证登录的爬虫,需要发布为Rest服务,然后发现Flask是一个很好的Web框架,使用Python语言实现。 1 安装flask pip install flask 2 编写简单的HelloWorld app py from flask import Flaskapp = Flask
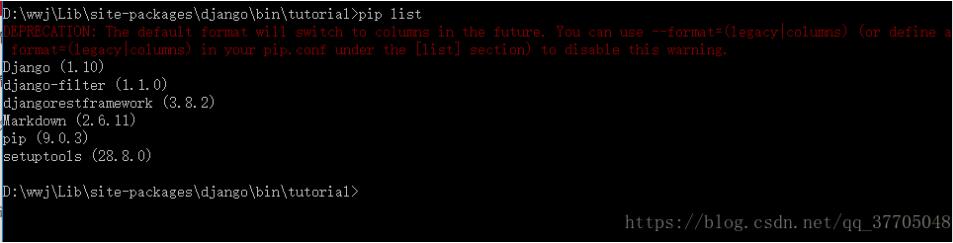
安装好所需要的插件和包: python、django、pip等版本如下: 采用Django REST框架3 0 1、在python文件夹下D: python Lib site-packages django bin打开cmd命令工具,本人将python文件夹名字改为了wwj,请注意: mkdir tu
本文实例为大家分享了python实现递归查找某个路径下所有文件中的中文字符,供大家参考,具体内容如下 -*- coding: utf-8 -*- @ description: @ author: @ created: 2018 7 21 import reimport sysimport os relo

关于Django生成迁移文件,我是在虚拟机上完成的 1 创建虚拟环境: 在终端上输入创建python3的虚拟环境 mkvirtualenv -p python3 虚拟环境的名字 在虚拟环境中安装好django1 8 4和pymysql 2 创建项目 创建项目语句:django
有时候运行Django的migrate命令不能创建INSTALLED_APPS中的app中的models py的数据库表, 这时可以先运行: python manage py makemigrations [appname] 这里的appname是指你需要指定django检查的app name, 运行该命
今天修改之前实习小伙伴写的js代码的时候,遇到修改后页面未发生变化的问题。因为我是web开发小白,所以上网查了一波,得以解决~~ 初次进行web工程开发的人可能会碰到这样的情况:自己在明明对工程上的某个js或css文件进行

在开发web的时候,如果是以前已存在的项目,项目下载下来后,为了使用测试库的数据,会直接将整个测试库(如sqlite3)拿到本机来。这种情况下,如果执行的顺序不对,很容易在执行migrate的时候出现数据库已存在的错误: django db
本文实例为大家分享了python实现复制大量文件的具体代码,供大家参考,具体内容如下 本来是去项目公司拷数据,结果去了发现有500G,靠系统的复制功能怕是得好几个小时,于是回来学一手操作,话不多说上代码: 说明:CopyFiles1是可
一个简易的TCP端口扫描器,使用python3实现。 需求:扫描目标网站开放哪些端口号,将所有开放的端口号输出。 分析:使用socket连接,如果连接成功,认为端口开放,如果连接失败,认为端口关闭(有可能端口开放但连接失败,这里简单认为