
python scrapy爬虫代码及填坑
涉及到详情页爬取 目录结构: kaoshi_bqg py import scrapyfrom scrapy spiders import Rulefrom scrapy linkextractors import LinkExtractorfrom items import BookBQGItemclass KaoshiBqgSpider(scrapy Spide
涉及到详情页爬取 目录结构: kaoshi_bqg py import scrapyfrom scrapy spiders import Rulefrom scrapy linkextractors import LinkExtractorfrom items import BookBQGItemclass KaoshiBqgSpider(scrapy Spide

目的:爬取阳光热线问政平台问题反映每个帖子里面的标题、内容、编号和帖子url CrawlSpider版流程如下: 创建爬虫项目dongguang scrapy startproject dongguang 设置items py文件 -*- coding: utf-8 -*-import sc

前言 最近学习scrapy爬虫框架,在使用pycharm安装scrapy类库及创建scrapy项目时花费了好长的时间,遇到各种坑,根据网上的各种教程,花费了一晚上的时间,终于成功,其中也踩了一些坑,现在整理下相关教程,希望帮助那些遇到和我一
scrapy写一个爬虫,爬取到了页面信息,由于某些原因需要检测获取字符串的编码格式,发现检测中提示了TypeError: Expected object of type bytes or bytearray, got: 这样的错误结果

win7+ python3.7 + scrapy1.5 + docker Toolbox + Splash v3.2 + scrapy-splash说明:Splash v3.2安装在docker Toolbox虚拟容器中,其他直接安装在win7系统
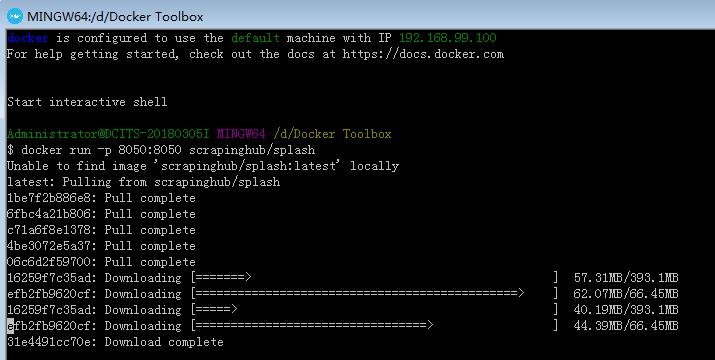
windows7 + Docker ToolBox + Scrapy Splash windows10 + 原生的Docker + Scrapy Splash 原生的Docker :系统要求,Windows10x64位,支持Hyper-V
一个scarpy简易的spider爬虫蜘蛛

执行scarpy爬虫蜘蛛提示import win32api ModuleNotFoundError No module named 'win32api'
执行类似scrapy startproject myScrapy_1命令,myScrapy_1为项目名称
提示错误:error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools